登 录
注 册
< 数 据 库
MySQL
ClickHouse
ES
Doris
MongoDB
Redis
其他DB
Doris概述
Doris扩容和缩容
Doris数据模型
Doris优化
热门推荐>>>
中台架构
中台建设与架构
Hadoop
源码分析-NN启动(三)
HBase
HBased对接Hive
Linux
Nginx高可用
Python
数据导出工具
Flink
3分钟搭建Flink SQL测试环境
Kafka
Kafka对接Flume
深度学习
卷积神经网络
数据结构与算法
选择合适的算法
MySQL
数据备份恢复
计算机系统
信号量同步线程
Hive
Hive调优参数大全
其他框架
Azkaban Flow1.0与2.0
ClickHouse
表引擎-其他类型
技术成长
最好的职业建议
精选书单
技术成长书单—机器学习
技术资讯
数据在线:计算将成为公共服务
开发工具
IntelliJ IDEA 20年发展回顾(二)
系统工具
Mac命令行工具
虚拟化
内存虚拟化概述
云原生
云原生构建现代化应用
云服务
一文搞懂公有云、私有云...
Java
Spring Boot依赖注入与Runners
Go
Go函数与方法
SQL
SQL模板
当前位置:
首页
>>
Doris
>>
Doris优化
Doris优化
2023-09-10 15:35:04 星期日 发表于北京 阅读:891
 Doris优化/利用查询执行的统计结果,可以更好的帮助我们了解 Doris 的执行情况,并有针对性的进行相应 Debug 与调优工作。 #### QueryProfile FE 将查询计划拆分成为 Fragment 下发到 BE 进行任务执行。BE 在执行 Fragment 时记录了运行状态时的统计值,并将 Fragment 执行的统计信息输出到日志之中。 FE 也可以通过开关将各个 Fragment 记录的这些统计值进行搜集,并在 FE 的 Web 页面上打印结果。 使用方法: 1) 开启 profile:`set enable_profile=true;` 2) 执行一个查询:`SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;` 3) 在webui查看:FE所在节点主机名:8030/QueryProfile/ #### Join Reorder Join Reorder 功能可以通过代价模型自动帮助调整 SQL 中 Join 的顺序,以帮助获得最优的 Join 效率。 可通过会话变量开启: ``` set enable_cost_based_join_reorder=true ``` ##### 原理 数据库一旦涉及到多表 Join,Join 的顺序对整个Join 查询的性能是影响很大的。假设有三张表 Join,参考下面这张图,左边是 a 表跟 b 张表先做 Join,中间结果的有 2000 行,然后与 c 表再进行 Join 计算。 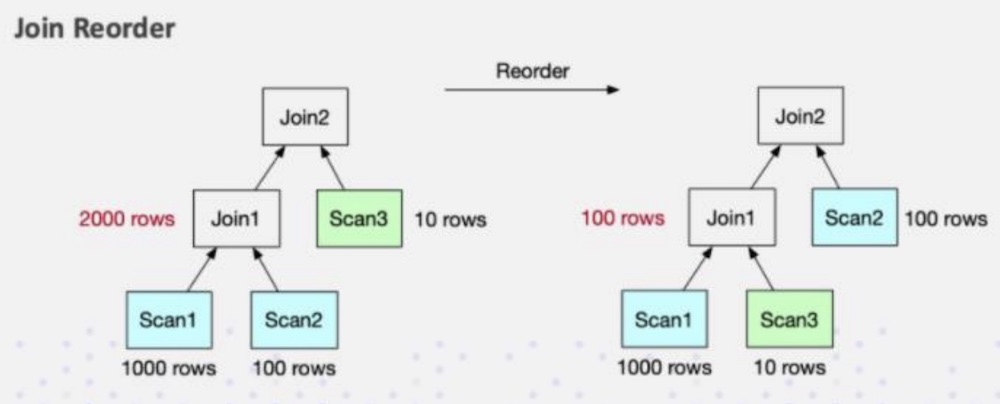 接下来看右图,把 Join 的顺序调整了一下。把 a 表先与 c 表 Join,生成的中间结果只有 100,然后最终再与 b 表 Join 计算。最终的 Join 结果是一样的,但是它生成的中间结果有 20 倍的差距,这就会产生一个很大的性能 Diff 了。 Doris 目前支持基于规则的 Join Reorder 算法。它的逻辑是: (1)让大表、跟小表尽量做 Join,它生成的中间结果是尽可能小的 (2)把有条件的 Join 表往前放,也就是说尽量让有条件的 Join 表进行过滤 (3)Hash Join 的优先级高于 Nest Loop Join,因为 Hash join 本身是比 Nest Loop Join快很多的 #### Join 的优化原则 (1)在做 Join 的时候,要尽量选择同类型或者简单类型的列,同类型的话就减少它的数据 Cast,简单类型本身 Join 计算就很快 (2)尽量选择 Key 列进行 Join, 原因前面在 Runtime Filter 的时候也介绍了,Key列在延迟物化上能起到一个比较好的效果 (3)大表之间的 Join ,尽量让它 Co-location ,因为大表之间的网络开销是很大的,如果需要去做 Shuffle 的话,代价是很高的 (4)合理的使用 Runtime Filter,它在 Join 过滤率高的场景下效果是非常显著的。但是它并不是万灵药,而是有一定副作用的,所以需要根据具体的 SQL 的粒度做开关 (5)涉及到多表 Join 的时候,需要去判断 Join 的合理性。尽量保证左表为大表,右表为小表,然后 Hash Join 会优于 Nest Loop Join。必要的时可以通过 SQL Rewrite,利用Hint 去调整 Join 的顺序 #### Bitmap 索引 用户可以通过创建 bitmap index 加速查询,特别是针对count distinct 指标 1)创建索引 ``` CREATE INDEX [IF NOT EXISTS] index_name ON table_name (column [, ...],) [USING BITMAP] [COMMENT"balabala"]; ``` 注意: BITMAP 索引仅在单列上创建 示例:在 table1 上为 siteid 创建 bitmap 索引 ``` CREATE INDEX table_bitmap ON table1 (siteid) USING BITMAP COMMENT "table1_bitmap_index"; ``` 2)查看索引 ``` SHOW INDEX[ES] FROM [db_name.]table_name [FROM database]; 或者 SHOW KEY[S] FROM [db_name.]table_name [FROM database]; 示例:展示 table1 索引 SHOW INDEX FROM test_db.table1; ``` 3)删除索引 ``` DROP INDEX [IF EXISTS] index_name ON [db_name.]table_name; 示例: DROP INDEX IF EXISTS table_bitmap ON test_db.table1; ``` #### BloomFilter 索引 Doris的BloomFilter索引是从通过建表的时候指定,或者通过表的ALTER操作来完成。 Bloom Filter 本质上是一种位图结构,用于快速的判断一个给定的值是否在一个集合中。这种判断会产生小概率的误判。即如果返回 false,则一定不在这个集合内。而如果范围 true,则有可能在这个集合内。 BloomFilter 索引也是以 Block 为粒度创建的。每个 Block 中,指定列的值作为一个集合生成一个 BloomFilter 索引条目,用于在查询是快速过滤不满足条件的数据。 在建表时指定bloom filter列,通过指定properties参数 ``` PROPERTIES ( "replication_num" = "3", "bloom_filter_columns"="saler_id,category_id", ... ) ``` 查看 BloomFilter 索引 `SHOW CREATE TABLE sale_detail_bloom` 修改 BloomFilter 索引 `ALTER TABLE test_db.sale_detail_bloom SET ("bloom_filter_columns"= "customer_id,sku_id");` 删除 BloomFilter 索引 `ALTER TABLE test_db.sale_detail_bloom SET ("bloom_filter_columns"= "");` #### 合理设置分桶分区数 (1)一个表的 Tablet 总数量等于 (Partition num * Bucket num) (2)一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量 (3)单个 Tablet 的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个 Tablet 数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加 Schema Change 或者 Rollup 操作失败重试的代价(这些操作失败重试的粒度是 Tablet) (4)当 Tablet 的数据量原则和数量原则冲突时,建议优先考虑数据量原则 (5)在建表时,每个分区的 Bucket 数量统一指定。但是在动态增加分区时(ADD PARTITION),可以单独指定新分区的 Bucket 数量。可以利用这个功能方便的应对数据缩小或膨胀 (6)一个 Partition 的 Bucket 数量一旦指定,不可更改。所以在确定 Bucket 数量时,需要预先考虑集群扩容的情况。比如当前只有 3 台 host,每台 host 有 1 块盘。如果Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,也不能提高并发度 (7)举一些例子:假设在有 10 台 BE,每台 BE 一块磁盘的情况下。如果一个表总大小为 500MB,则可以考虑 4-8 个分片。5GB:8-16 个。50GB:32 个。500GB:建议分区,每个分区大小在 50GB 左右,每个分区 16-32 个分片。5TB:建议分区,每个分区大小在50GB 左右,每个分区 16-32 个分片 注:表的数据量可以通过 show data 命令查看,结果除以副本数,即表的数据量

 京公网安备 11010902000544号
京公网安备 11010902000544号