登 录
注 册
< 大 数 据
Flink
Hadoop
Spark
Hive
HBase
Kafka
其他框架
Kerberos服务介绍与部署
Hadoop HA简介
HDFS手动故障转移
HDFS手动故障转移示例
HDFS自动故障转移
YARN自动故障转移
Hadoop白名单与扩容
HDFS存储优化-纠删码
HDFS冷热存储分离
HDFS慢磁盘监控
HDFS小文件归档
源码分析-NN启动(一)
源码分析-NN启动(二)
源码分析-NN启动(三)
热门推荐>>>
中台架构
中台建设与架构
HBase
HBased对接Hive
Linux
Nginx高可用
Python
数据导出工具
Flink
3分钟搭建Flink SQL测试环境
Kafka
Kafka对接Flume
深度学习
卷积神经网络
数据结构与算法
选择合适的算法
MySQL
数据备份恢复
计算机系统
信号量同步线程
Hive
Hive调优参数大全
其他框架
Azkaban Flow1.0与2.0
ClickHouse
表引擎-其他类型
技术成长
最好的职业建议
精选书单
技术成长书单—机器学习
技术资讯
数据在线:计算将成为公共服务
开发工具
IntelliJ IDEA 20年发展回顾(二)
系统工具
Mac命令行工具
虚拟化
内存虚拟化概述
云原生
云原生构建现代化应用
云服务
一文搞懂公有云、私有云...
Java
Spring Boot依赖注入与Runners
Go
Go函数与方法
SQL
SQL模板
安全常识
一文读懂SSO
当前位置:
首页
>>
Hadoop
>>
HDFS小文件归档
HDFS小文件归档
2021-07-25 11:52:39 星期日 阅读:2515
#### HDFS小文件问题 每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会耗尽NameNode中的大部分内存。 但注意,存储小文件所需要的磁盘容量和数据块的大小无关。例如,一个1MB的文件设置为128MB的块存储,实际使用的是1MB的磁盘空间,而不是128MB 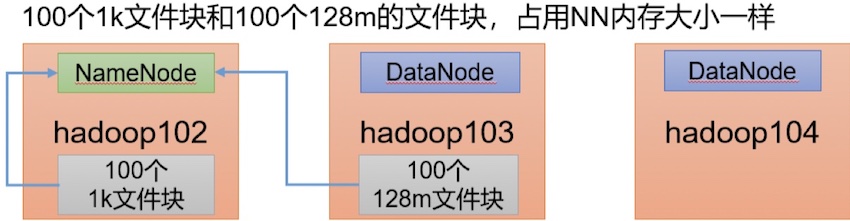 #### HAR文件 HDFS存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。 `具体说来,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。` 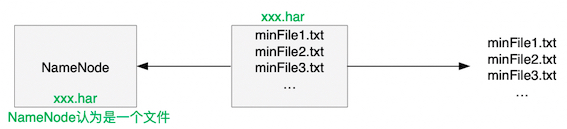 #### 案例 把HDFS的/input目录里面的所有文件归档成一个叫input.har的归档文件,并把归档后的文件存储到/output路径下 ```shell # 首先需要启动Yarn进程,因为归档过程中涉及计算 start-yarn.sh hadoop archive -archiveName input.har -p/input/output ``` 查看归档后的文件 ```shell hadoop fs -ls /output/input.har ``` 使用har协议查看归档文件中包含的所有小文件 ```shell hadoop fs -ls har:///output/input.har ``` 解归档文件 ```shell # 把input.har包含的所有小文件复制到hdfs /tmp目录下 hadoop fs -cp har:///output/input.har/* /tmp ```

 京公网安备 11010902000544号
京公网安备 11010902000544号