登 录
注 册
< 大 数 据
Flink
Hadoop
Spark
Hive
HBase
Kafka
其他框架
Flink本地程序开发
Flink实战-数据准备
Flink实战-自定义Sink
Flink实战-实时计算
Flink实战-部署上线
文件映射为Table
FlinkTable自定义函数
Flink API JOIN总结
Flink SQL JOIN总结
3分钟搭建Flink SQL测试环境
热门推荐>>>
中台架构
中台建设与架构
Hadoop
源码分析-NN启动(三)
HBase
HBased对接Hive
Linux
Nginx高可用
Python
数据导出工具
Kafka
Kafka对接Flume
深度学习
卷积神经网络
数据结构与算法
选择合适的算法
MySQL
数据备份恢复
计算机系统
信号量同步线程
Hive
Hive调优参数大全
其他框架
Azkaban Flow1.0与2.0
ClickHouse
表引擎-其他类型
技术成长
最好的职业建议
精选书单
技术成长书单—机器学习
技术资讯
数据在线:计算将成为公共服务
开发工具
IntelliJ IDEA 20年发展回顾(二)
系统工具
Mac命令行工具
虚拟化
内存虚拟化概述
云原生
云原生构建现代化应用
云服务
一文搞懂公有云、私有云...
Java
Spring Boot依赖注入与Runners
Go
Go函数与方法
SQL
SQL模板
安全常识
一文读懂SSO
当前位置:
首页
>>
Flink
>>
Flink本地程序开发
Flink本地程序开发
2020-07-02 13:20:30 星期四 阅读:14022
 #####创建maven项目 用Intellij IDEA或者Visual Studio Code均可 #####配置maven环境 注意:setting.xml文件里面默认是国外的中央仓库,build的时候会非常慢,建议改成阿里云的,如下配置: ``` <mirror>xml <id>nexus-aliyun</id> <mirrorOf>*</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror> ``` 使用IDEA创建Flink项目(如下图) 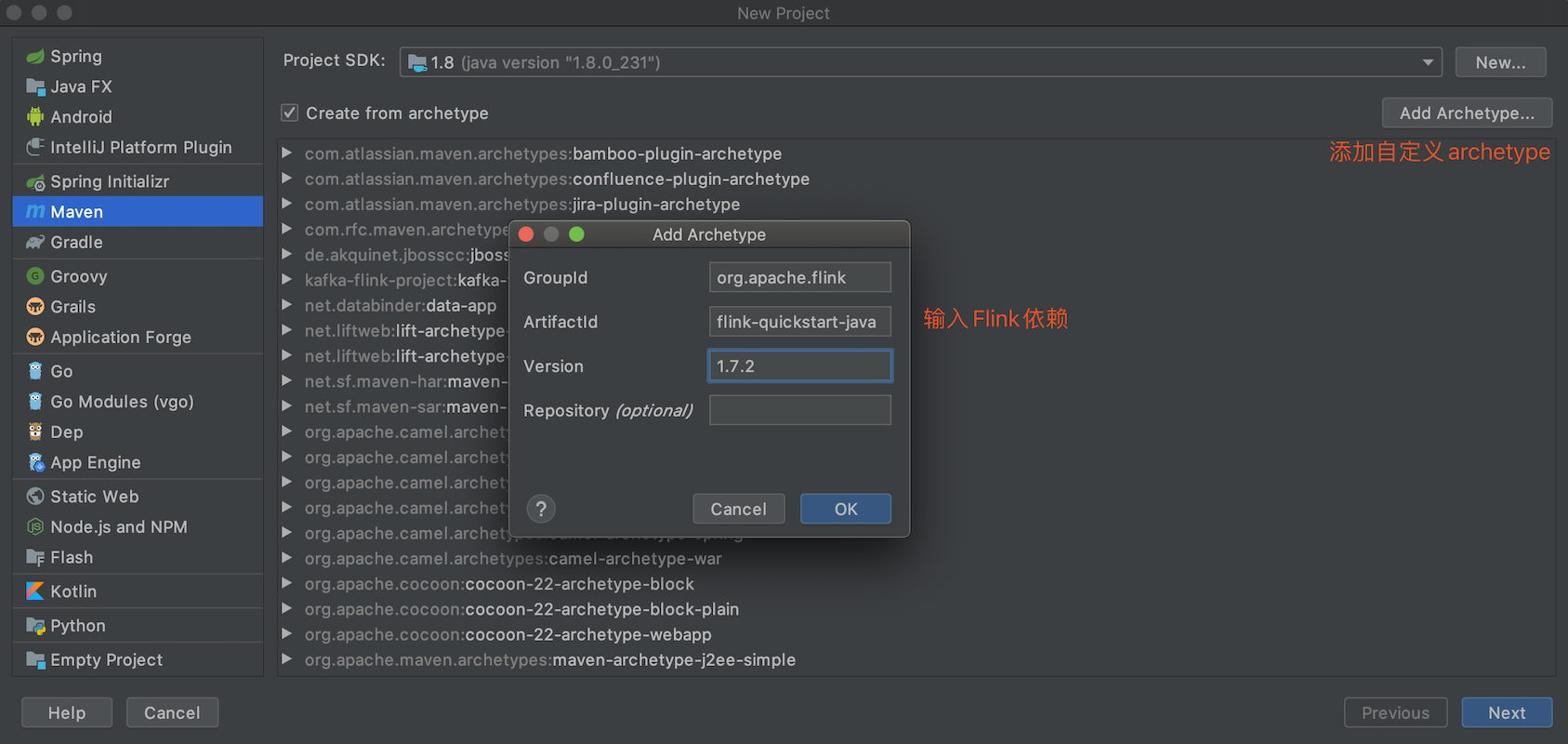 #####构建成功后的项目结构如下 ``` 14:37:47|libins ~/vscode$ tree my-kafka-flink-project/ my-kafka-flink-project/ ├── my-kafka-flink-project.iml ├── pom.xml └── src └── main ├── java │ └── cn │ └──libins │ ├── BatchJob.java │ └── StreamingJob.java └── resources └── log4j.properties 6 directories, 5 files ``` #####编写WordCount程序 在源文件目录下创建Java文件SocketWindowWordCount.java ```java package cn.libins; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector; public class SocketWindowWordCount { public static void main(String[] args) throws Exception { // 创建 execution environment final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 通过连接 socket 获取输入数据,这里连接到本地9000端口,如果9000端口已被占用,请换一个端口 DataStream<String> text = env.socketTextStream("localhost", 9000, " "); // 解析数据,按 word 分组,开窗,聚合 DataStream<Tuple2<String, Integer>> windowCounts = text .flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) { for (String word : value.split("s")) { out.collect(Tuple2.of(word, 1)); } } }) .keyBy(0) .timeWindow(Time.seconds(5)) .sum(1); // 将结果打印到控制台,注意这里使用的是单线程打印,而非多线程 windowCounts.print().setParallelism(1); env.execute("Socket Window WordCount"); } } ``` #####执行程序 执行时需要注意两点: - 1、在IDE执行上面创建的main方法之前。先配置下Run/Debug属性,勾选依赖。具体操作步骤是: 右键main方所在的Java文--->选择"Edit SocketWindow..."选项--->在弹出的对话框中勾选Include dependencies with "provided scope" 2、一定先开启9000端口再执行main方法,否则Java程序报错(Connection Refused) 本地终端开启9000端口,模拟生产数据:`$ nc -lk 9000` 在开启的9000端口终端输入一些测试单词,在IDE的输出控制台能够实时看到统计的结果

 京公网安备 11010902000544号
京公网安备 11010902000544号