登 录
注 册
< 大 数 据
Flink
Hadoop
Spark
Hive
HBase
Kafka
其他框架
Flink本地程序开发
Flink实战-数据准备
Flink实战-自定义Sink
Flink实战-实时计算
Flink实战-部署上线
文件映射为Table
FlinkTable自定义函数
Flink API JOIN总结
Flink SQL JOIN总结
3分钟搭建Flink SQL测试环境
热门推荐>>>
中台架构
中台建设与架构
Hadoop
源码分析-NN启动(三)
HBase
HBased对接Hive
Linux
Nginx高可用
Python
数据导出工具
Kafka
Kafka对接Flume
深度学习
卷积神经网络
数据结构与算法
选择合适的算法
MySQL
数据备份恢复
计算机系统
信号量同步线程
Hive
Hive调优参数大全
其他框架
Azkaban Flow1.0与2.0
ClickHouse
表引擎-其他类型
技术成长
最好的职业建议
精选书单
技术成长书单—机器学习
技术资讯
数据在线:计算将成为公共服务
开发工具
IntelliJ IDEA 20年发展回顾(二)
系统工具
Mac命令行工具
虚拟化
内存虚拟化概述
云原生
云原生构建现代化应用
云服务
一文搞懂公有云、私有云...
Java
Spring Boot依赖注入与Runners
Go
Go函数与方法
SQL
SQL模板
安全常识
一文读懂SSO
当前位置:
首页
>>
Flink
>>
Flink SQL JOIN总结
Flink SQL JOIN总结
2024-01-07 16:32:44 星期日 发表于北京 阅读:1860
 在流处理中,动态表的Join对应着两条数据流的Join操作。Flink SQL中的联结查询大体上也可以分为两类:SQL原生的联结查询方式,和流处理中特有的联结查询 #### 一、常规联结查询(Regular JOIN) 常规联结是SQL中原生定义的Join方式,是最通用的一类联结操作。它的具体语法与标准SQL的联结完全相同,通过关键字JOIN来联结两个表,后面用关键字ON来指明联结条件。 与标准SQL一致,Flink SQL的常规联结也可以分为**内联结(INNER JOIN)**和**外联结(OUTER JOIN)**,区别在于结果中是否包含不符合联结条件的行。 Regular Join 包含以下几种(以 L 作为左流中的数据标识, R 作为右流中的数据标识) | JOIN方式 | 说明 | | ------------ | ------------ | | Inner Join(Inner Equal Join) | 流任务中,只有两条流 Join 到才输出,输出 +[L, R] | | Left Join(Outer Equal Join) | 流任务中,左流数据到达之后,无论有没有 Join 到右流的数据,都会输出(Join 到输出 +[L, R] ,没 Join 到输出 +[L, null] ),如果右流之后数据到达之后,发现左流之前输出过没有 Join 到的数据,则会发起回撤流,先输出 -[L, null] ,然后输出 +[L, R] | |Right Join(Outer Equal Join)| 与Left Join 一样,左表和右表的执行逻辑完全相反| |Full Join(Outer Equal Join)|流任务中,左流或者右流的数据到达之后,无论有没有 Join 到另外一条流的数据,都会输出(对右流来说:Join 到输出 +[L, R] ,没 Join 到输出 +[null, R] ;对左流来说:Join 到输出 +[L, R] ,没 Join 到输出 +[L, null] )。如果一条流的数据到达之后,发现之前另一条流之前输出过没有 Join 到的数据,则会发起回撤流(左流数据到达为例:回撤 -[null, R] ,输出+[L, R] ,右流数据到达为例:回撤 -[L, null] ,输出 +[L, R]| **Regular注意事项**: 流的上游是无限的数据,Flink 会将两条流的所有数据都存储在 State 中,所以 Flink 任务的 State 会无限增大,因此需要为 State 配置合适的 TTL,以防止 State 过大 #### 二、间隔联结查询(Interval JOIN) 目前,Flink DataStream API中的双流Join已支持窗口联结(window join)和间隔联结(interval join) 但在Flink SQL中,两条流的Join就对应着SQL中两个表的Join,这是流处理中特有的联结方式,Flink SQL当前还不支持窗口联结,而间隔联结则已经实现 **间隔联结(Interval Join)返回的,同样是符合约束条件的两条中数据的笛卡尔积。只不过这里的“约束条件”除了常规的联结条件外,还多了一个时间间隔的限制**,具体语法要点如下: ##### 1.两表的联结 间隔联结不需要用JOIN关键字,直接在FROM后将要联结的两表列出来就可以,用逗号分隔。这与标准SQL中的语法一致,表示一个“交叉联结”(Cross Join),会返回两表中所有行的笛卡尔积。当然,如果要用JOIN关键字也可以 ##### 2.联结条件 联结条件用WHERE子句来定义,用一个等值表达式描述。交叉联结之后再用WHERE进行条件筛选,效果跟内联结INNER JOIN ... ON ...非常类似 ##### 3.时间间隔限制 WHERE子句中,联结条件后用AND追加一个时间间隔的限制条件,提取左右两侧表中的时间字段,然后用一个表达式来指明两者需要满足的间隔限制 用法演示(两种写法等价) ```sql -- 写法1 SELECT s1.user_id ,s2.user_id FROM source1 s1 JOIN source2 s2 ON s1.row_time BETWEEN s2.row_time - interval "2" second AND s2.row_time + interval "5" second --写法2 SELECT s1.user_id ,s2.user_id FROM source1 s1, source2 s2 WHERE s1.row_time BETWEEN s2.row_time - interval "2" second AND s2.row_time + interval "5" second ``` 可通过Flink WEB UI看到JOIN的算子是Interval JOIN 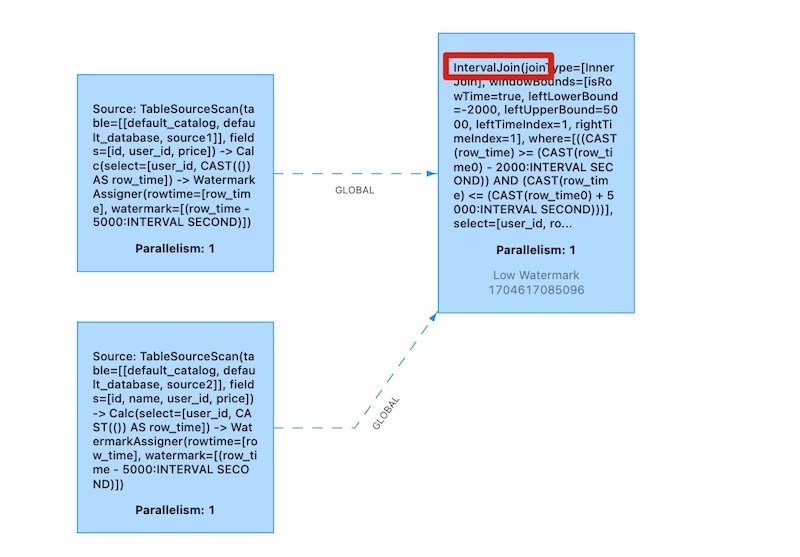 #### 三、维表联结查询(Lookup Join) Lookup Join 其实就是维表 Join,实时获取外部缓存的 Join,Lookup 的意思就是实时查找 上面说的这几种 Join 都是流与流之间的 Join,而 Lookup Join 是流与 Redis,Mysql,HBase 这种外部存储介质的 Join 注意:`Lookup JOIN仅支持处理时间字段` 关联语法 ``` SELECT o.order_id, o.total, c.country, c.zip FROM Orders AS o JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c ON o.customer_id = c.id; ``` 在这里,订单实时流与 MySQL维表通过id关联获取维度信息

 京公网安备 11010902000544号
京公网安备 11010902000544号