登 录
注 册
< 大 数 据
Flink
Hadoop
Spark
Hive
HBase
Kafka
其他框架
Flink本地程序开发
Flink实战-数据准备
Flink实战-自定义Sink
Flink实战-实时计算
Flink实战-部署上线
文件映射为Table
FlinkTable自定义函数
Flink API JOIN总结
Flink SQL JOIN总结
3分钟搭建Flink SQL测试环境
热门推荐>>>
中台架构
中台建设与架构
Hadoop
源码分析-NN启动(三)
HBase
HBased对接Hive
Linux
Nginx高可用
Python
数据导出工具
Kafka
Kafka对接Flume
深度学习
卷积神经网络
数据结构与算法
选择合适的算法
MySQL
数据备份恢复
计算机系统
信号量同步线程
Hive
Hive调优参数大全
其他框架
Azkaban Flow1.0与2.0
ClickHouse
表引擎-其他类型
技术成长
最好的职业建议
精选书单
技术成长书单—机器学习
技术资讯
数据在线:计算将成为公共服务
开发工具
IntelliJ IDEA 20年发展回顾(二)
系统工具
Mac命令行工具
虚拟化
内存虚拟化概述
云原生
云原生构建现代化应用
云服务
一文搞懂公有云、私有云...
Java
Spring Boot依赖注入与Runners
Go
Go函数与方法
SQL
SQL模板
安全常识
一文读懂SSO
当前位置:
首页
>>
Flink
>>
3分钟搭建Flink SQL测试环境
3分钟搭建Flink SQL测试环境
2024-01-07 17:14:45 星期日 发表于北京 阅读:1944
 在实际工作中,对于某些实时流场景,有很多实验性的想法、线上问题由于没有快速支持的测试环境,验证、复现非常困难,主要存在如下痛点: - **1.无符合对应场景的实验数据,自己写完造数据的脚本,可能半天过去了** - **2.没有即用即停的Flink测试环境,使用公司线上环境又无法与自己造的数据打通** 而这些问题,Flink官方都为我们想到了,以下分两部分介绍搭建过程,即:一键搭建本地执行环境,一键生成稳定测试数据 #### 一键搭建本地执行环境 ##### 1.下载Flink编译好的二进制包 **环境说明:** Flink版本:1.12.2 本地环境:Mac OS **下载地址:https://archive.apache.org/dist/flink/** *注意:Flink官网只支持最新稳定版本下载,如果要下载历史版本,请点击本文档给的链接即可 * ##### 2.本地解压并启动集群 ``` # 解压 tar -zxvf flink-1.12.2-bin-scala_2.12.tgz -C ~/software/ # 启动集群 cd ~/software/flink-1.12.2/ bin/start-cluster.sh # 停止集群 bin/stop-cluster.sh ``` 启动日志 >Starting cluster. Starting standalonesession daemon on host 192.168.1.4. Starting taskexecutor daemon on host 192.168.1.4. **启动验证** 启动集群的同时, Flink会同步启动Web UI页面,可访问本地8081端口验 http://localhost:8081/#/overview 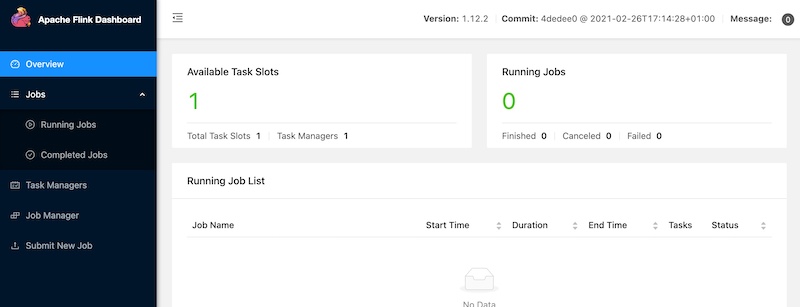 ##### 3.启动TaskManager(可选) 在Flink集群启动时,会默认启动1个TaskManager,如果你需要的测试环境需要多并行度验证,可通过如下命令启动多个TM(执行一次命令启动一个) ``` # 启动TM bin/taskmanager.sh start # 停止TM bin/taskmanager.sh stop # 停止全部TM bin/taskmanager.sh stop-all ``` 启动日志 >[INFO] 1 instance(s) of taskexecutor are already running on 192.168.1.4. Starting taskexecutor daemon on host 192.168.1.4. 启动成功后可通过Flink Web UI查看启动效果 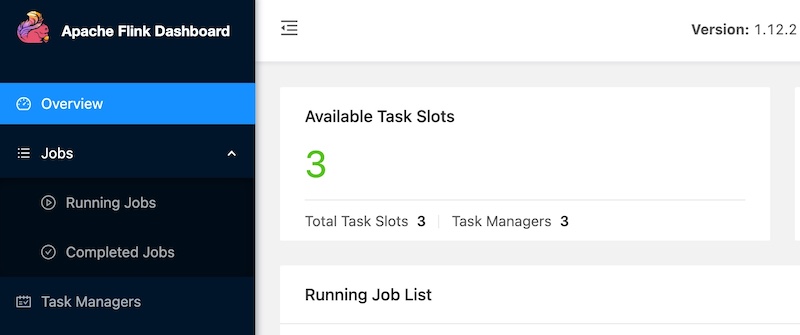 #### 一键生成稳定测试数据 Flink内置的`datagen`连接器为我们提供了个性化的数据生成器,可通过with参数控制需要生成数据的格式、数据量等 ##### 1.启动Flink SQL Client ``` bin/sql-client.sh embedded ``` 启动成功后,就进入了Flink SQL命令行界面 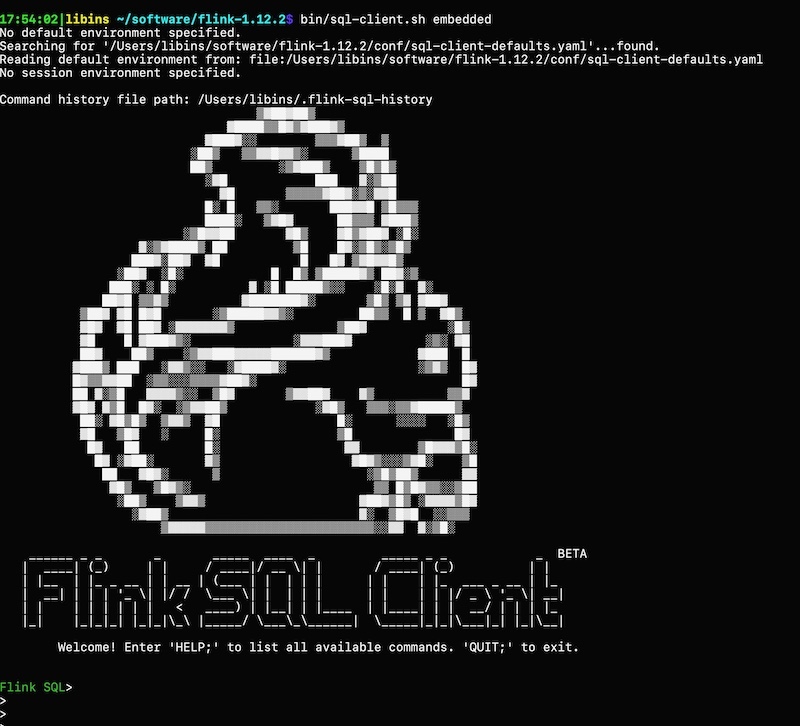 ##### 2.编辑数据源参数 这里以生成订单数据流为例,包含 **id、user_id、product_id、product_name、price**字段,并以当前系统时间为事件时间, watermark设置为事件时间向前推5秒 具体字段的参数及含义如下 ```sql CREATE TABLE order_source ( id bigint, user_id bigint, product_id bigint, product_name string, price bigint, row_time as cast(current_timestamp as timestamp(3)), watermark for row_time as row_time - interval '5' second ) WITH ( 'connector' = 'datagen', -- 固定写法 'rows-per-second' = '10', -- 每秒生成10条数据 'fields.id.min' = '1', -- id字段最小值 'fields.id.max' = '1000000', -- id字段最最大值 'fields.user_id.min' = '10001', -- user_id字段最小值 'fields.user_id.max' = '99999990', -- user_id字段最大值 'fields.product_id.min' = '101', -- product_id字段最小值 'fields.product_id.max' = '200', -- product_id字段最大值 'fields.product_name.length' = '10',-- product_name字段长度 'fields.price.min' = '1000', -- price字段最小值 'fields.price.max' = '9999' -- price字段最大值 ); ``` ##### 3.查询验证 ``` Flink SQL> select * from order_source; ``` 可看到数据按照配置的参数在持续生成 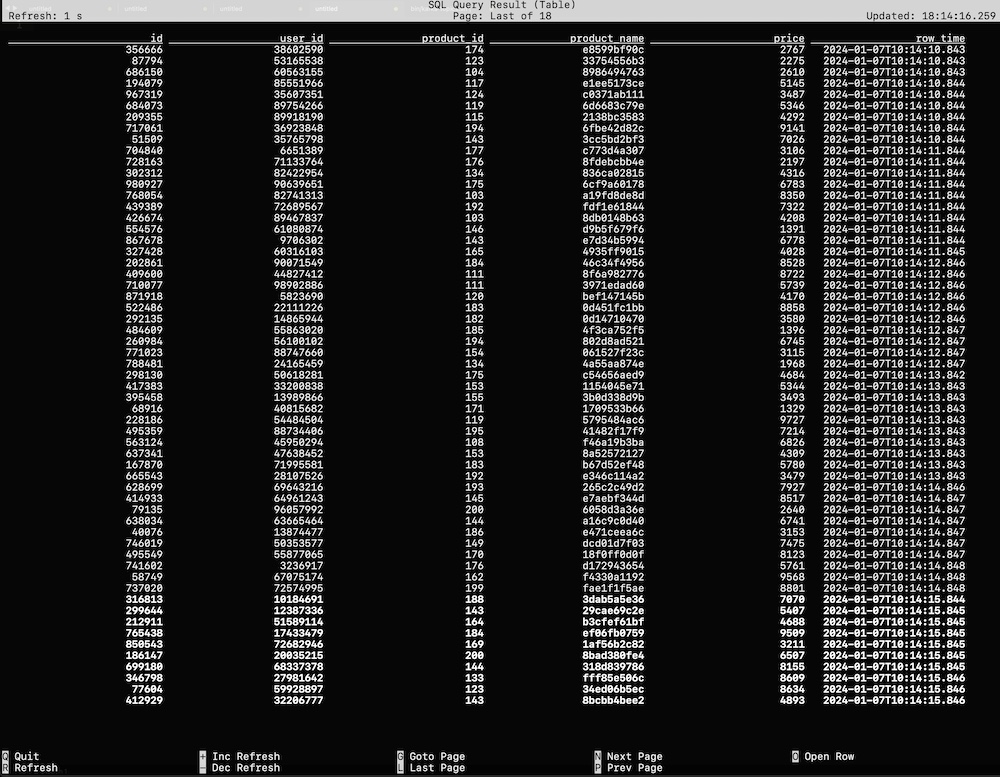 同时,也可通过Flink Web UI页面查看正在执行的SELECT任务 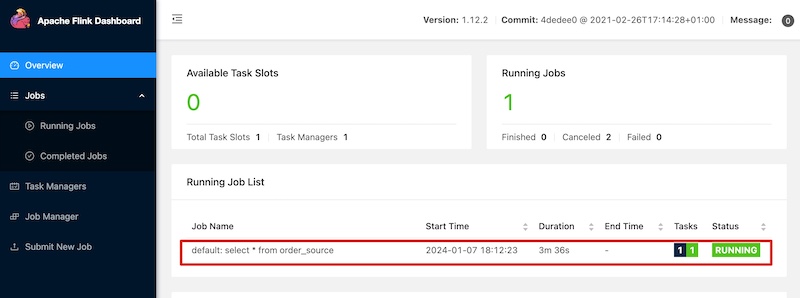 **至此,测试数据生成完毕,可根据具体的测试、验证场景调节需要生成数据的相关参数** ##### 4.快速生成sink表(可选) 如果某些测试任务暂时不方便将数据写入到数据库或者kafka队列,那么也可以`使用Flink自带的print连接器`将计算好的数据输出到控制台以验证加工逻辑是否符合预期 创建Slink表 ```sql CREATE TABLE aggr_order_info( product_id bigint, price_sum bigint ) WITH ( 'connector' = 'print' ); ``` 实时加工逻辑 ```sql INSERT INTO aggr_order_info SELECT product_id, sum(price) as price_sum FROM order_source GROUP BY product_id; ``` 提交日志 >[INFO] Submitting SQL update statement to the cluster... [INFO] Table update statement has been successfully submitted to the cluster: Job ID: fd845ab922ad013d7889c3fbe5464d9a Flink Web UI验证输出结果 

 京公网安备 11010902000544号
京公网安备 11010902000544号