登 录
注 册
< 大 数 据
Flink
Hadoop
Spark
Hive
HBase
Kafka
其他框架
Flink本地程序开发
Flink实战-数据准备
Flink实战-自定义Sink
Flink实战-实时计算
Flink实战-部署上线
文件映射为Table
FlinkTable自定义函数
Flink API JOIN总结
Flink SQL JOIN总结
3分钟搭建Flink SQL测试环境
热门推荐>>>
中台架构
中台建设与架构
Hadoop
源码分析-NN启动(三)
HBase
HBased对接Hive
Linux
Nginx高可用
Python
数据导出工具
Kafka
Kafka对接Flume
深度学习
卷积神经网络
数据结构与算法
选择合适的算法
MySQL
数据备份恢复
计算机系统
信号量同步线程
Hive
Hive调优参数大全
其他框架
Azkaban Flow1.0与2.0
ClickHouse
表引擎-其他类型
技术成长
最好的职业建议
精选书单
技术成长书单—机器学习
技术资讯
数据在线:计算将成为公共服务
开发工具
IntelliJ IDEA 20年发展回顾(二)
系统工具
Mac命令行工具
虚拟化
内存虚拟化概述
云原生
云原生构建现代化应用
云服务
一文搞懂公有云、私有云...
Java
Spring Boot依赖注入与Runners
Go
Go函数与方法
SQL
SQL模板
安全常识
一文读懂SSO
当前位置:
首页
>>
Flink
>>
FlinkTable自定义函数
FlinkTable自定义函数
2020-11-15 17:15:12 星期日 阅读:4244
#### Flink自定义函数的种类 为了方便理解,下表列出了每种自定义函数在Hive中与之对应的函数类型 | 序号 | Flink自定义函数类型 | 解释 | 对应Hive函数 | | ------------ | ------------ | ------------ | ------------ | | 1 | UDF用户自定义函数 | 输入一行,输出一行 | SUBSTR | | 2 | UDTF用户自定义表函数 | 输入一行,输出多行 | EXPLODE | | 3 | UDAF用户自定义聚合函数 | 输入多行,输出一行 | SUM/AVG/MAX... | | 4 | UDTAF用户自定义表聚合函数 | 输入多行,输出多行 | ROW_NUMBER OVER | 四种自定义函数的实现方式由易到难。关于四种聚合函数的开发示例请参见官方帮助文档:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/functions/udfs.html 这里先展示第一种自定义函数的实现方式。 ####需求描述 1、Flink读取文件内容(文件内容如下图)并将数据流映射为FlinkTable表A 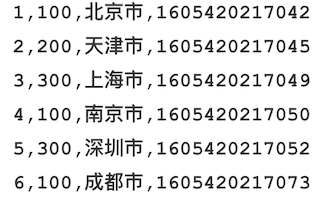 2、通过FlinkSQL查询表A的数据,并将city字段通过自定义函数取hash值显示。 所以,该自定义函数的功能就是:`接收一个参数,求该参数的hash值并返回` ####环境准备 Flink Version 1.10.0 Java Version 1.8 ####代码实现 ```java package cn.libins; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.typeinfo.TypeHint; import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.api.java.tuple.Tuple4; import org.apache.flink.api.java.tuple.Tuple5; import org.apache.flink.streaming.api.TimeCharacteristic; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.java.StreamTableEnvironment; import org.apache.flink.table.functions.ScalarFunction; public class UDFTest { public static void main(String[] args) throws Exception { String filepath = "/home/flink-table-api.csv"; StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime); // 将输入文件内容映射为数据流,并按照逗号分隔展开 DataStream inputDataStream = env.readTextFile(filepath).map(new MapFunction<String, Tuple4<Integer, Integer, String, Long>>() { @Override public Tuple4<Integer, Integer, String, Long> map(String s) throws Exception { String[] stringArray = s.split(","); return Tuple4.of(Integer.valueOf(stringArray[0]), Integer.valueOf(stringArray[1]), stringArray[2], Long.valueOf(stringArray[3])); } }); // 将流映射为Flink Table,并定义字段名称 StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); Table inputTable = tableEnv.fromDataStream(inputDataStream, "id, typeId, city, ts"); tableEnv.createTemporaryView("tempTable", inputTable); // 注册UDF函数 MyHashCode myHashCode = new MyHashCode(10); tableEnv.registerFunction("myHashCode", myHashCode); // 通过Flink SQL调用UDF函数 Table resultTable = tableEnv.sqlQuery("SELECT id, typeId, city, myHashCode(city) as hasCity, ts FROM tempTable"); // 将查询结果转换为数据流并输出 DataStream ds = tableEnv.toRetractStream(resultTable, TypeInformation.of(new TypeHint<Tuple5<Integer, Integer, String, Integer, Long>>() {})); ds.print(); env.execute("Flink Table UDF test job"); } // 自定义函数类 public static class MyHashCode extends ScalarFunction { private int factor; // 用户自定义的hash因子 public MyHashCode(Integer factor) { this.factor = factor; } public int eval(String s) { return s.hashCode() * factor; } } } ``` ####执行结果 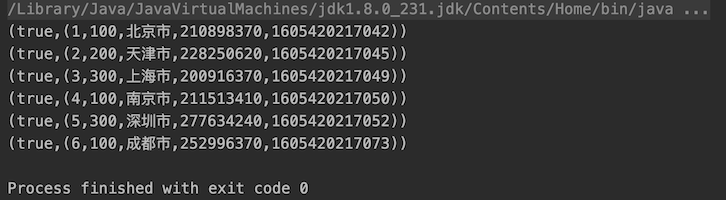

 京公网安备 11010902000544号
京公网安备 11010902000544号