登 录
注 册
< 系统运维
Linux
计算机系统
系统工具
系统硬件组成
高速缓存
存储器及操作系统
Amdahl定理
信息表示和处理
内存有关错误
全球IP因特网
信号量同步线程
热门推荐>>>
中台架构
中台建设与架构
Hadoop
源码分析-NN启动(三)
HBase
HBased对接Hive
Linux
Nginx高可用
Python
数据导出工具
Flink
3分钟搭建Flink SQL测试环境
Kafka
Kafka对接Flume
深度学习
卷积神经网络
数据结构与算法
选择合适的算法
MySQL
数据备份恢复
Hive
Hive调优参数大全
其他框架
Azkaban Flow1.0与2.0
ClickHouse
表引擎-其他类型
技术成长
最好的职业建议
精选书单
技术成长书单—机器学习
技术资讯
数据在线:计算将成为公共服务
开发工具
IntelliJ IDEA 20年发展回顾(二)
系统工具
Mac命令行工具
虚拟化
内存虚拟化概述
云原生
云原生构建现代化应用
云服务
一文搞懂公有云、私有云...
Java
Spring Boot依赖注入与Runners
Go
Go函数与方法
SQL
SQL模板
安全常识
一文读懂SSO
当前位置:
首页
>>
计算机系统
>>
高速缓存
高速缓存
2020-07-05 12:07:36 星期日 阅读:2705
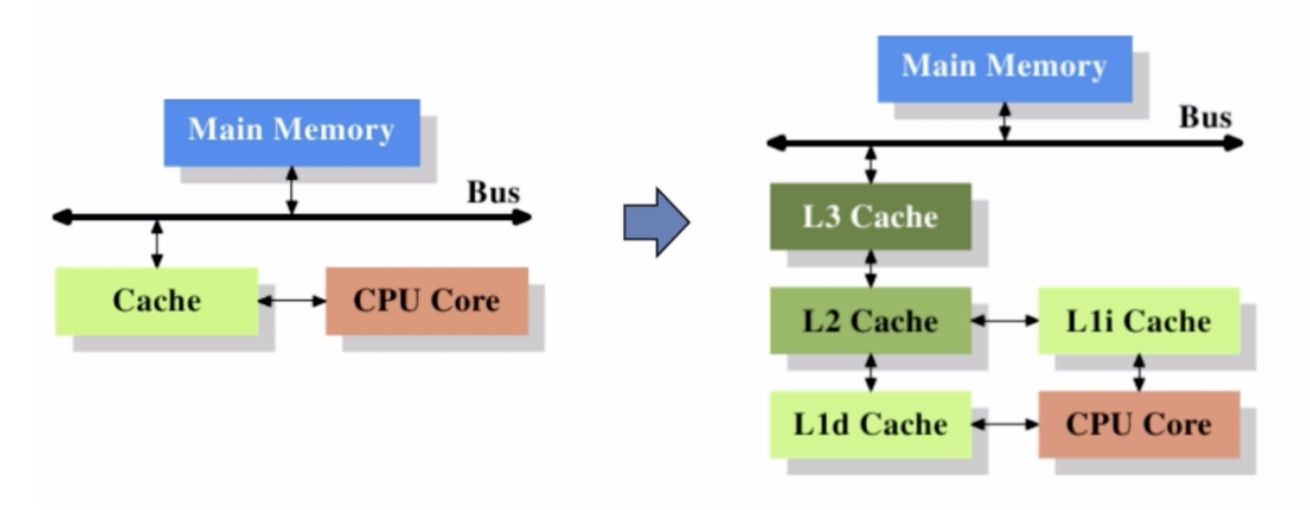 缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU运算速度要比内存读写速度快很多,这样会使CPU花费很长时间等待数据到来或把数据写入内存。 当我们在运行HelloWord程序的时候,shell会执行一系列的指令来加载可执行的hello文件,这些指令将hello目标文件中的代码和数据从磁盘复制到主存,数据包括最终会被输出的字符串“hello,world "。一旦目标文件hello中的代码和数据被加载到主存,处理器就开始执行hello程序的main程序中的机器语言指令。这些指令将“hello world ”字符串中的字节从主存复制到寄存器文件,再从寄存器文件中复制到显示设备,最终显示在屏幕上。 上面的示例揭示了一个很重要的问题,即`花费了大量的时间把信息从一个地方挪到另一个地方`: hello程序的机器指令最初放在磁盘上,当程序加载时,他们被复制到主存,当处理器运行程序时,指令又从主存复制到处理器。最后又从主存复制到显示设备。这从程序员的角度来看,这些复制就是开销,降低程序的执行效率。 根据机械原理,`较小的存储设备要比较大的存储设备运行得快`。而快速设备的造价远高于同类的低速设备。比如:一个典型系统上的磁盘可能比主存容量大1000倍,但是对于处理器而言,从磁盘上读取一个字的时间开销要比从主存中读取开销大1000万倍。类似的,一个典型的寄存器文件只存储几百字节的信息,而主存里可以存放几十亿字节。然而,处理器从寄存器文件中读取数据比从主存中读取几乎要快100倍。这些年半导体技术的进步,这种处理器与主存之间的差距还在持续增大,因为加快处理器的运行速度比加快主存的运行速度要容易和便宜得多。 针对这种处理器与主存之间的差异,系统设计者采用了更小更快的存储设备,称为`高速缓存存储器`(cache memory),存放处理器近期可能会需要的信息。位于处理器芯片上的`L1高速缓存的容量可以达到数万字节,访问速度几乎和访问寄存器文件一样快`。一个容量为数十万到数百万字节的更大的L2高速缓存通过一条特殊的总线连接到处理器。进行访问L2的速度比访问L1的速度慢5倍,但是这仍然比访问主存的时间快5至10倍。L1和L2高速缓存是用一种叫静态随机访问存储器(SRAM)的硬件技术来实现的。现在比较新的,处理能力更强的系统甚至有三级高速缓存:L1、L2和L3。系统可以获得一个很大的存储器,同时访问速度也很快,原因是利用了高速缓存的局部性原理,即程序具有访问局部区域里的数据和代码的趋势。通过让高速缓存里存放可能经常访问的数据。大部分的内存操作都能在快速的高速缓存中完成。 结论:`程序员能够利用高速缓存存储器将程序的性能提高一个数量级。`

 京公网安备 11010902000544号
京公网安备 11010902000544号