登 录
注 册
< 人工智能
深度学习
机器学习
大模型
ChatGPT是怎样炼成的
大模型的知识处理
被神话的语言模型衍生品
热门推荐>>>
中台架构
中台建设与架构
Hadoop
源码分析-NN启动(三)
HBase
HBased对接Hive
Linux
Nginx高可用
Python
数据导出工具
Flink
3分钟搭建Flink SQL测试环境
Kafka
Kafka对接Flume
深度学习
卷积神经网络
数据结构与算法
选择合适的算法
MySQL
数据备份恢复
计算机系统
信号量同步线程
Hive
Hive调优参数大全
其他框架
Azkaban Flow1.0与2.0
ClickHouse
表引擎-其他类型
技术成长
最好的职业建议
精选书单
技术成长书单—机器学习
技术资讯
数据在线:计算将成为公共服务
开发工具
IntelliJ IDEA 20年发展回顾(二)
系统工具
Mac命令行工具
虚拟化
内存虚拟化概述
云原生
云原生构建现代化应用
云服务
一文搞懂公有云、私有云...
Java
Spring Boot依赖注入与Runners
Go
Go函数与方法
SQL
SQL模板
当前位置:
首页
>>
大模型
>>
ChatGPT是怎样炼成的
ChatGPT是怎样炼成的
2023-09-17 18:46:44 星期日 发表于北京 阅读:1736
 一个模型的参数数量越多,通常意味着该模型可以处理更复杂、更丰富的信息,具备更高的准确性和表现力。这是因为更多的参数可以提供更多的自由度,使模型可以更好地适应训练数据,并更好地进行泛化,也就是能够处理新的、以前没有见过的数据,可以在更广泛的应用场景中发挥作用。 然而,大型模型的训练和推理过程需要更多的计算资源和时间,并且需要更多的数据来进行有效的训练。因此,在选择适当的模型时需要平衡计算资源、数据可用性和性能要求等因素。 #### GPT系列模型的参数量 |序号|版本|参数说明| |-|-|-| |1|GPT-1|OpenAI于2018年发布的第一个生成式预训练语言模型,它有117M(1.17亿)个参数| |2|GPT-2|OpenAI于2019年发布的语言模型,它是GPT-1的进一步改进,有1.5B(15亿)个参数| |3|GPT-3|OpenAI于2020年发布的语言模型,其模型参数数量达到了175B(1750亿)| |4|InstructGPT|OpenAI于2021年发布的语言模型,它针对对话系统任务进行了微调,有1.3B(13亿)个参数 |5|ChatGPT3.5|OpenAI于2022年发布的语言模型,<br>目前并未公布其参数量,根据ChatGPT的推理速度和Azure硬件能力,推测其模型大小应该小于GPT-3,大于InstructGPT| |6|GPT-4|OpenAI于2023年3月发布的模型,参数量并未公布,根据推理速度推测,其参数量明显大于GPT3.5| #### 大模型预训练的数据来源 GPT系列模型用过的数据集有以下几类:`维基百科、图书、杂志期刊、Reddit链接、Common Crawl和其他`。在GPT-3中使用的数据集大小有700多GB,5000亿左右的token数量 ##### 维基百科 是一个免费的多语言协作在线百科全书,由30多万志愿者共同编写和维护。截至2022年4月,英文版维基百科超过了640万篇文章,包含单词数超40亿。这个数据集很有价值,因为其文本来源引用非常严谨,以说明性文字形式写成,并且跨越多种语言和领域。 ##### 图书数据集 由小说和非小说书籍组成,可用于训练模型的故事叙述及回应能力 ##### 杂志期刊中的论文 学术写作通常是方法论、理性和一丝不苟的输出。其中包括类似ArXiv论文库和美国国家卫生研究院(The National Institutes of Health)的数据集 ##### WebText,Reddit出站链接数据集 其数据是从社交媒体平台Reddit所有出站链接网络中爬取的,每个链接至少有三个用户的点赞,可以代表内容的流行风向标。 ##### Common Crawl使用互联网爬虫技术 每月对互联网上约10亿个网页进行爬取。截至2021年9月,Common Crawl存档的数据集总大小超过70PB(70万亿字节),包含超过1000亿个网页的数据 ##### 其他 GitHub等代码数据集。从语种角度分析,只看其中数据量最大的Common Crawl,数据主要是英语,约占46%,中文、俄语、德语、日语等其他语言各占约5%。 #### 什么是生成式AI 生成式AI(Generative AI)是一种人工智能技术,它可以生成新的文本、图像、声音、视频、方案模拟(simulation)等多种类型的数据。 **生成式AI与传统的机器学习算法不同** |AI类型|学习算法| |-|-| |传统的分析型AI|通过训练数据来学习预测新数据的标签或值| |`生成式AI`|通过学习数据的概率分布来生成新的数据| 生成式AI的技术不仅包括GPT,生成式对抗网络(GAN)也是生成式AI技术的代表性算法,其基本思想是同时训练两个神经网络: `一个生成器网络和一个判别器网络` 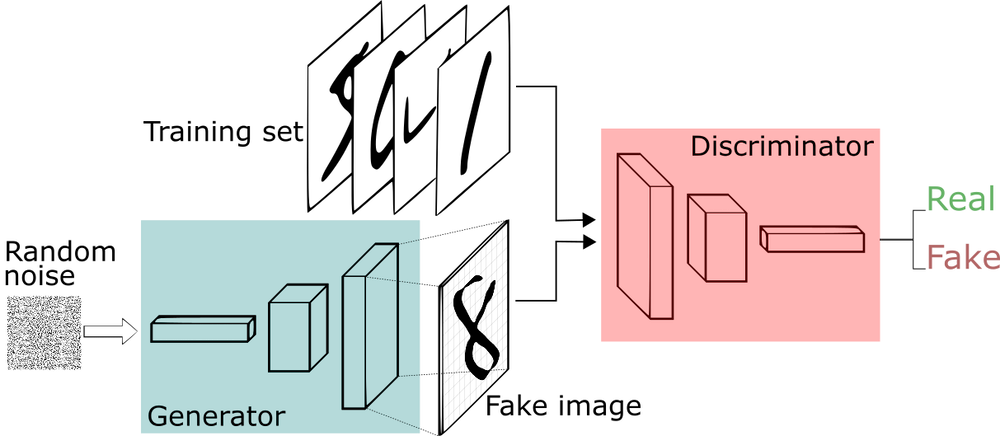 生成器网络用于生成假数据,判别器网络用于区分真实数据和生成的假数据。两个网络不断交替训练,直到生成器网络生成的假数据无法被判别器网络区分真假为止。 GAN已经被广泛应用于图像生成、视频生成、音频生成等领域,还可以在工业领域进行生成式设计(GenerativeDesign),通过模拟和优化设计空间中的多种解决方案来生成最优化的设计,帮助设计师快速探索多个解决方案,从而节省时间和成本,提高设计的效率和质量。在生成式设计中,设计师首先定义问题的输入参数和限制条件,然后通过算法生成多个可能的设计方案,并使用评价函数来评估每个方案的质量。随后,算法会根据评价函数的反馈来自动调整设计方案,从而不断优化最终的设计结果。 ---- 参考书籍:《大模型时代:ChatGPT》开启通用人工智能浪潮

 京公网安备 11010902000544号
京公网安备 11010902000544号