登 录
注 册
< 大 数 据
Flink
Hadoop
Spark
Hive
HBase
Kafka
其他框架
HBase读写流程
多租户环境
HBase HA
HBase预分区
RowKey设计
HBase优化
HBase数据删除与Split
HBase PythonAPI
HBase存储结构
HBased对接Hive
热门推荐>>>
中台架构
中台建设与架构
Hadoop
源码分析-NN启动(三)
Linux
Nginx高可用
Python
数据导出工具
Flink
3分钟搭建Flink SQL测试环境
Kafka
Kafka对接Flume
深度学习
卷积神经网络
数据结构与算法
选择合适的算法
MySQL
数据备份恢复
计算机系统
信号量同步线程
Hive
Hive调优参数大全
其他框架
Azkaban Flow1.0与2.0
ClickHouse
表引擎-其他类型
技术成长
最好的职业建议
精选书单
技术成长书单—机器学习
技术资讯
数据在线:计算将成为公共服务
开发工具
IntelliJ IDEA 20年发展回顾(二)
系统工具
Mac命令行工具
虚拟化
内存虚拟化概述
云原生
云原生构建现代化应用
云服务
一文搞懂公有云、私有云...
Java
Spring Boot依赖注入与Runners
Go
Go函数与方法
SQL
SQL模板
安全常识
一文读懂SSO
当前位置:
首页
>>
HBase
>>
HBase数据删除与Split
HBase数据删除与Split
2021-12-25 11:13:10 星期六 阅读:1120
 #### HBase真正删除数据的时间 我们在HBase客户端通过put覆盖数据,或者通过delete某一行数据的时候,HBase底层并没有真实的删除数据,只是做一个标记(其实删除数据的时候还是执行插入操作,只是插入的数据是标记)。在刚删除完数据一会还可以通过以下命令查看删除的数据 `hbase(main):001:0> scan "tablename", {RAW=>TRUE, VERSIONS=>10}` **HBase真正删除数据的时机有两个**,分别是: `Flush操作`:将内存中的数据写到HDFS的时候,会把用户已经删除的数据过滤掉(实际上,用户删除的数据在内存中还存在的)。对于覆盖操作,只会把最新版本的数据Flush到hdfs;对于delete操作,只会把delete标记写入到hdfs。 `Compact操作(全局 Compact)`:定期合并HFile文件的时候,会把多个HFile文件中相同记录(rowkey相同,列名相同,但是版本不同)的数据合并,根据时间戳对比取最新版本的数据保留。对于delete标签标记的数据,hbase会把多个HFile文件中相同记录(rowkey相同,列名相同)的数据删除后再合并。 注意:Min Compact操作不会删除数据,只有全局合并的时候会删除。 #### HBase Region Split 默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入,Region 会自动进行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考虑, HMaster 有可能会将某个 Region 转移给其他的 Region Server。 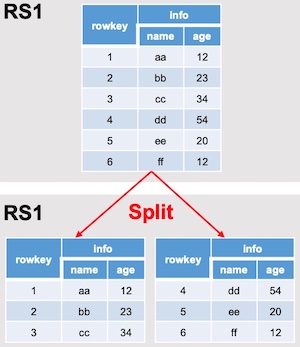 **Region Split 时机**: 1.当 1 个 region 中的某个 Store 下所有 StoreFile 的总大小超过 hbase.hregion.max.filesize, 该 Region 就会进行拆分(0.94 版本之前)。 2.当 1 个 region 中的某个 Store 下所有 StoreFile 的总大小超过 `Min(R^2 * "hbase.hregion.memstore.flush.size",hbase.hregion.max.filesize")`,该 Region 就会进行拆分,其 中 R 为当前 Region Server 中属于该 Table 的个数(0.94 版本之后)。

 京公网安备 11010902000544号
京公网安备 11010902000544号