登 录
注 册
< 人工智能
深度学习
机器学习
大模型
机器学习应用示例
机器学习系统类型
机器学习主要挑战
热门推荐>>>
中台架构
中台建设与架构
Hadoop
源码分析-NN启动(三)
HBase
HBased对接Hive
Linux
Nginx高可用
Python
数据导出工具
Flink
3分钟搭建Flink SQL测试环境
Kafka
Kafka对接Flume
深度学习
卷积神经网络
数据结构与算法
选择合适的算法
MySQL
数据备份恢复
计算机系统
信号量同步线程
Hive
Hive调优参数大全
其他框架
Azkaban Flow1.0与2.0
ClickHouse
表引擎-其他类型
技术成长
最好的职业建议
精选书单
技术成长书单—机器学习
技术资讯
数据在线:计算将成为公共服务
开发工具
IntelliJ IDEA 20年发展回顾(二)
系统工具
Mac命令行工具
虚拟化
内存虚拟化概述
云原生
云原生构建现代化应用
云服务
一文搞懂公有云、私有云...
Java
Spring Boot依赖注入与Runners
Go
Go函数与方法
SQL
SQL模板
当前位置:
首页
>>
机器学习
>>
机器学习主要挑战
机器学习主要挑战
2023-09-17 17:04:54 星期日 发表于北京 阅读:1703
 本文简述机器学习过程中,影响学习效果的几大因素 #### 训练数据的数量不足 大部分机器学习算法需要大量的数据才能正常工作。即使是最简单的问题,很可能也需要成千上万个示例,而对于诸如图像或语音识别等复杂问题,则可能需要数百万个示例(除非你可以重用现有模型的某些部分) **`对复杂问题而言,数据比算法更重要`**,但中小型数据集依然非常普遍,获得额外的训练数据并不总是一件轻而易举或物美价廉的事情,所以算法上的改进也同样非常重要 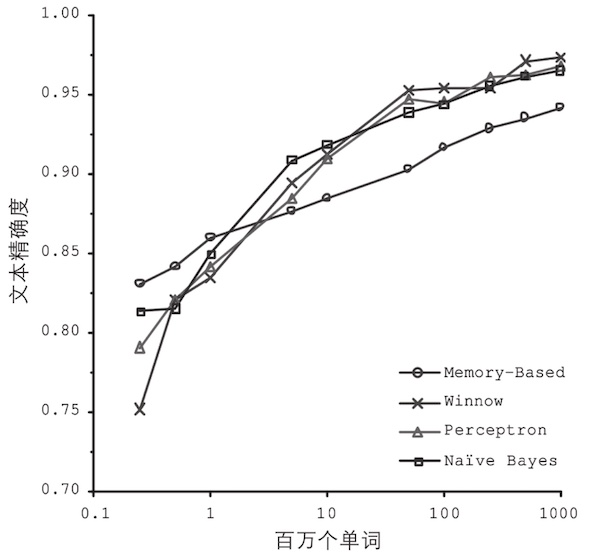 #### 训练数据不具代表性 为了很好地实现泛化,至关重要的一点是对于将要泛化的新示例来说,训练数据一定要非常有代表性。无论你使用的是基于实例的学习还是基于模型的学习,都是如此。 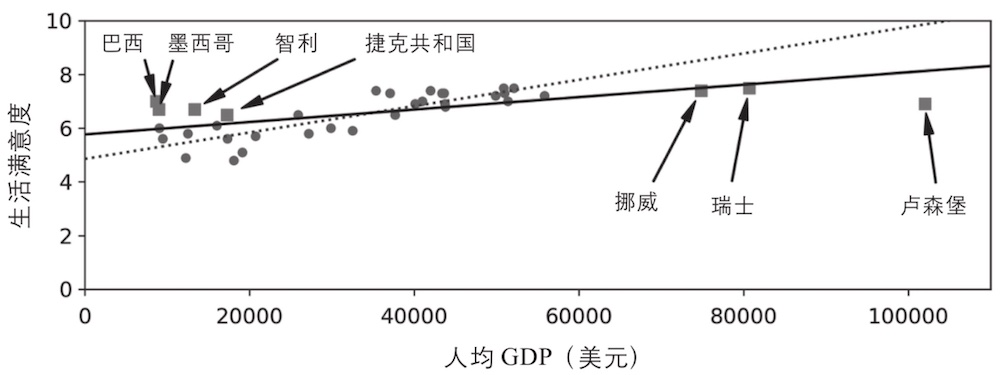 使用不具代表性的训练集训练出来的模型不可能做出准确的预估,尤其是极端情况(如上图:针对那些特别贫穷或特别富裕的国家) **针对你想要泛化的案例使用具有代表性的训练集**,这一点至关重要。不过说起来容易,做起来难: >如果样本集太小,将会出现采样噪声(即非代表性数据被选中) 而即便是非常大的样本数据,如果采样方式欠妥,也同样可能导致非代表性数据集,这就是所谓的采样偏差。 #### 低质量数据 显然,如果训练集满是错误、异常值和噪声(例如,低质量的测量产生的数据),系统将更难检测到底层模式,更不太可能表现良好。所以花时间来清理训练数据是非常值得的投入。 事实上,大多数数据科学家都会花费很大一部分时间来做这项工作,例如: >如果某些实例明显是异常情况,那么直接将其丢弃,或者尝试手动修复错误,都会大有帮助。 如果某些实例缺少部分特征(例如,5%的顾客没有指定年龄),你必须决定是整体忽略这些特征、忽略这部分有缺失的实例、将缺失的值补充完整(例如,填写年龄值的中位数),还是训练一个带这个特征的模型,再训练一个不带这个特征的模型 #### 无关特征 正如我们常说的:垃圾入,垃圾出。只有训练数据里包含足够多的相关特征以及较少的无关特征,系统才能够完成学习。一个成功的机器学习项目,其关键部分是提取出一组好的用来训练的特征集。这个过程叫作特征工程,包括以下几点: |过程|解释 | |-|-| |特征选择|从现有特征中选择最有用的特征进行训练| |特征提取|将现有特征进行整合,产生更有用的特征——正如前文提到的,降维算法可以提供帮助| |通过收集新数据创建新特征| —| #### 过拟合训练数据 在机器学习中,过拟合,也就是指模型在训练数据上表现良好,但是泛化时却不尽如人意。 ##### 过拟合发生原因 当模型相对于训练数据的数量和噪度都过于复杂时,会发生过拟合。 ##### 可能的解决方案 |方案|解释| |-|-| |简化模型|可以选择较少参数的模型(例如,选择线性模型而不是高阶多项式模型)也可以减少训练数据中的属性数量,或者是约束模型| |收集更多的训练数据| —| |减少训练数据中的噪声|例如,修复数据错误和消除异常值| #### 欠拟合训练数据 欠拟合和过拟合正好相反。它的产生通常是因为对于底层的数据结构来说,模型太过简单。解决这个问题的主要方式有: >1. 选择一个带有更多参数、更强大的模型 2. 给学习算法提供更好的特征集(特征工程) 3. 减少模型中的约束(例如,减少正则化超参数)

 京公网安备 11010902000544号
京公网安备 11010902000544号