登 录
注 册
< 人工智能
深度学习
机器学习
大模型
机器学习应用示例
机器学习系统类型
机器学习主要挑战
热门推荐>>>
中台架构
中台建设与架构
Hadoop
源码分析-NN启动(三)
HBase
HBased对接Hive
Linux
Nginx高可用
Python
数据导出工具
Flink
3分钟搭建Flink SQL测试环境
Kafka
Kafka对接Flume
深度学习
卷积神经网络
数据结构与算法
选择合适的算法
MySQL
数据备份恢复
计算机系统
信号量同步线程
Hive
Hive调优参数大全
其他框架
Azkaban Flow1.0与2.0
ClickHouse
表引擎-其他类型
技术成长
最好的职业建议
精选书单
技术成长书单—机器学习
技术资讯
数据在线:计算将成为公共服务
开发工具
IntelliJ IDEA 20年发展回顾(二)
系统工具
Mac命令行工具
虚拟化
内存虚拟化概述
云原生
云原生构建现代化应用
云服务
一文搞懂公有云、私有云...
Java
Spring Boot依赖注入与Runners
Go
Go函数与方法
SQL
SQL模板
当前位置:
首页
>>
机器学习
>>
机器学习系统类型
机器学习系统类型
2023-09-17 16:22:59 星期日 发表于北京 阅读:1603
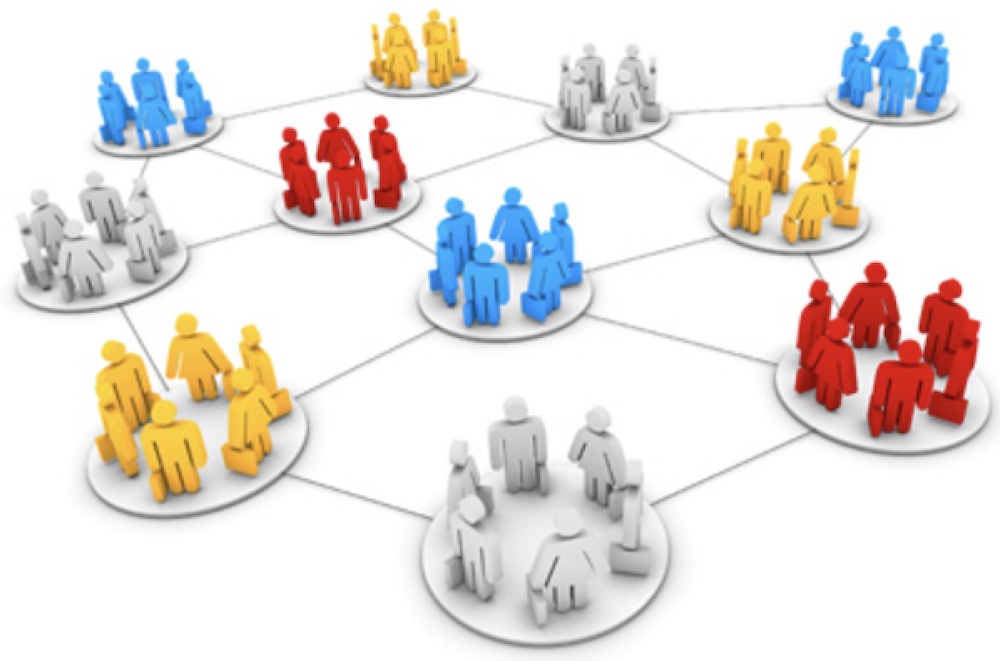 现有的机器学习系统类型繁多,为便于理解,我们根据以下标准将它们进行大的分类 >1.否在人类监督下训练(有监督学习、无监督学习、半监督学习和强化学习) >2.否可以动态地进行增量学习(在线学习和批量学习) >3.简单地将新的数据点和已知的数据点进行匹配,还是像科学家那样,对训练数据进行模式检测然后建立一个预测模型(基于实例的学习和基于模型的学习) #### 有监督学习和无监督学习 根据训练期间接受的监督数量和监督类型,可以将机器学习系统分为以下四个主要类别:`有监督学习、无监督学习、半监督学习和强化学习` ##### 有监督学习 监督学习是指在给定的训练集中“学习”出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果 监督学习的训练集要求包括输入和输出,即特征值和目标值(标签),训练集中数据的目标值(标签)是由人工事先进行标注的。 简单地说,监督学习是**包含自变量和因变量(有Y)**,同时可以用于分类和回归 监督学习的步骤如下 ###### 准备数据 监督学习首先要准备数据,没有现成的数据就需要采集数据或者爬取数据,或者从网站上下载数据。可以将准备好的数据集分为训练集、验证集和测试集。训练集是用来训练模型的数据集,验证集是确保模型没有过拟合的数据集,测试集是用来评估模型效果的数据集。 ###### 数据预处理 数据预处理主要包括重复数据检测、数据标准化、数据编码、缺失值处理、异常值处理等。 ###### 特征提取和特征选择 特征提取是结合任务自身特点,通过结合和转换原始特征集,构造出新的特征。特征选择是从大规模的特征空间中提取与任务相关的特征。特征提取和特征选择都是对原始数据进行降维的方法,从而去除数据的无关特征和冗余特征。 ###### 训练模型 模型就是函数,训练模型就是利用已有的数据,通过一些方法确定函数的参数。 ###### 评价模型 对于同一问题会有不同的数学模型,通过模型指标的比较来选取最优模型;对同一数学模型,通过模型指标的比较来调整模型参数。模型评价的基本思路是采用交叉验证方法。 ##### 常见的有监督学习算法 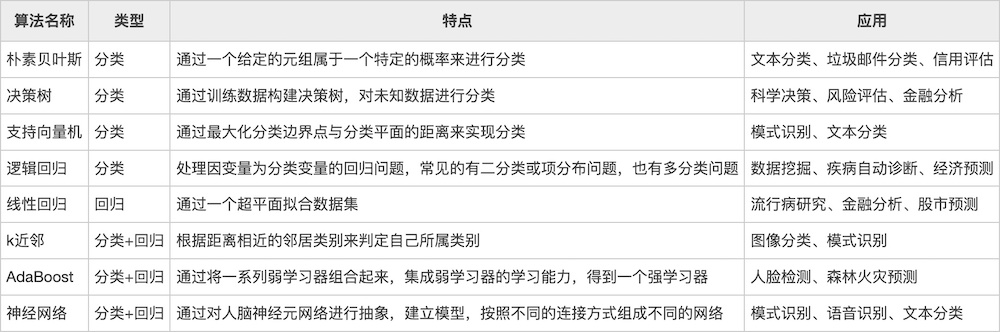 ##### 无监督学习 ###### 无监督学习的定义 非监督学习是指在机器学习过程中,用来训练机器的数据是没有标签的,机器只能依靠自己不断探索,对知识进行归纳和总结,尝试发现数据中的内在规律和特征,从而对训练数据打标签。 ###### 非监督学习的任务 非监督学习的训练数据是无标签的,非监督学习的目标是对观察值进行分类或者区分。 常见的非监督学习算法主要有三种:聚类、降维和关联。聚类算法是非监督学习中最常用的算法,它将观察值聚成一个一个的组,每个组都含有一个或几个特征。聚类的目的是将相似的东西聚在一起,而并不关心这类东西具体是什么。降维指减少一个数据集的变量数量,同时保证传达信息的准确性。关联指的是发现事物共现的概率。 ##### 常见的无监督学习算法 

 京公网安备 11010902000544号
京公网安备 11010902000544号