登 录
注 册
< 大 数 据
Flink
Hadoop
Spark
Hive
HBase
Kafka
其他框架
Spark简介
Spark开发环境初始化
Spark运行架构与核心组件
Spark RDD详解
Spark RDD转换算子-单Value类型
Spark RDD转换算子-其他类型
Spark RDD行动算子
Spark Shuffle的设计思想
Spark SQL Hints用法总结
热门推荐>>>
中台架构
中台建设与架构
Hadoop
源码分析-NN启动(三)
HBase
HBased对接Hive
Linux
Nginx高可用
Python
数据导出工具
Flink
3分钟搭建Flink SQL测试环境
Kafka
Kafka对接Flume
深度学习
卷积神经网络
数据结构与算法
选择合适的算法
MySQL
数据备份恢复
计算机系统
信号量同步线程
Hive
Hive调优参数大全
其他框架
Azkaban Flow1.0与2.0
ClickHouse
表引擎-其他类型
技术成长
最好的职业建议
精选书单
技术成长书单—机器学习
技术资讯
数据在线:计算将成为公共服务
开发工具
IntelliJ IDEA 20年发展回顾(二)
系统工具
Mac命令行工具
虚拟化
内存虚拟化概述
云原生
云原生构建现代化应用
云服务
一文搞懂公有云、私有云...
Java
Spring Boot依赖注入与Runners
Go
Go函数与方法
SQL
SQL模板
当前位置:
首页
>>
Spark
>>
Spark开发环境初始化
Spark开发环境初始化
2023-09-10 19:36:49 星期日 发表于北京 阅读:1164
 本文介绍IDEA开发Spark程序的一些初始化工作 #### 创建Maven工程 ##### 添加Spark核心依赖 ``` <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.0.0</version> </dependency> </dependencies> ``` ##### 创建WordCount类 以下代码不进行具体的统计操作,只进行spark开发环境是否就绪测试。即:获取到context后就调用close关闭了。 ``` package cn.libins.learn.spark.core import org.apache.spark.{SparkConf, SparkContext} object WorkCount { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount") val sc = new SparkContext(sparkConf) sc.stop() } } ``` 运行后上面的main程序,如果控制台打印的信息正常,则说明spark开发环境已经OK,如下图 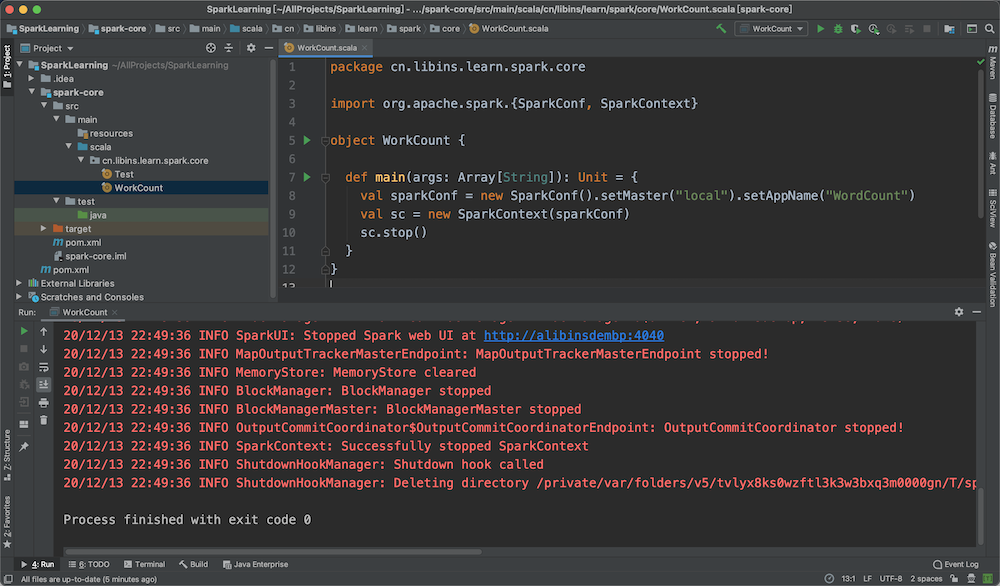 ##### 实现WordCount功能 在创建测试文本文件,并写入测试单词 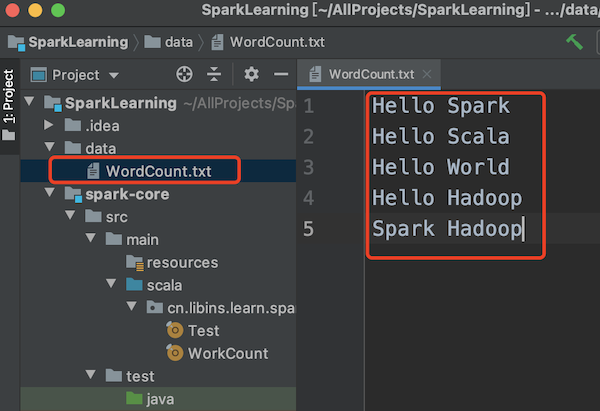 编写Scala代码,实现文件读取、分隔和统计的功能 ``` package cn.libins.learn.spark.core import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object WorkCount { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount") val sc = new SparkContext(sparkConf) // 读取文件内容、分隔并拼接1 val lines: RDD[String] = sc.textFile("data/WordCount.txt") val words: RDD[String] = lines.flatMap(_.split(" ")) val wordToOne = words.map(word => (word, 1)) // reduceByKey:相同key的数据,可以对value进行reduce聚合 val wordToCount = wordToOne.reduceByKey((x, y) => { x + y }) // 打印输出 val tuples = wordToCount.collect() tuples.foreach(println) sc.stop() } } ``` 控制台输出 ``` (Spark,2) (Hello,4) (World,1) (Scala,1) (Hadoop,2) ``` ##### 控制台日志过滤 在IDE执行Spark程序的时候,控制台会打印很多信息,为了方便查看程序的真实输出结果,可在项目的resources目录下创建log4j.properties文件,并添加如下参数解决  具体添加的参数如下 ``` log4j.rootCategory=ERROR, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/ddHH:mm:ss} %p %c{1}: %m%n # Set the default spark-shell log level to ERROR. When running the spark-shell, the # log level for this class is used to overwrite the root logger"s log level, so that # the user can have different defaults for the shell and regular Spark apps. log4j.logger.org.apache.spark.repl.Main=ERROR # Settings to quiet third party logs that are too verbose log4j.logger.org.spark_project.jetty=ERROR log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR log4j.logger.org.apache.parquet=ERROR log4j.logger.parquet=ERROR # SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive suppor log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR ```

 京公网安备 11010902000544号
京公网安备 11010902000544号