登 录
注 册
< 大 数 据
Flink
Hadoop
Spark
Hive
HBase
Kafka
其他框架
Spark简介
Spark开发环境初始化
Spark运行架构与核心组件
Spark RDD详解
Spark RDD转换算子-单Value类型
Spark RDD转换算子-其他类型
Spark RDD行动算子
Spark Shuffle的设计思想
Spark SQL Hints用法总结
热门推荐>>>
中台架构
中台建设与架构
Hadoop
源码分析-NN启动(三)
HBase
HBased对接Hive
Linux
Nginx高可用
Python
数据导出工具
Flink
3分钟搭建Flink SQL测试环境
Kafka
Kafka对接Flume
深度学习
卷积神经网络
数据结构与算法
选择合适的算法
MySQL
数据备份恢复
计算机系统
信号量同步线程
Hive
Hive调优参数大全
其他框架
Azkaban Flow1.0与2.0
ClickHouse
表引擎-其他类型
技术成长
最好的职业建议
精选书单
技术成长书单—机器学习
技术资讯
数据在线:计算将成为公共服务
开发工具
IntelliJ IDEA 20年发展回顾(二)
系统工具
Mac命令行工具
虚拟化
内存虚拟化概述
云原生
云原生构建现代化应用
云服务
一文搞懂公有云、私有云...
Java
Spring Boot依赖注入与Runners
Go
Go函数与方法
SQL
SQL模板
当前位置:
首页
>>
Spark
>>
Spark RDD详解
Spark RDD详解
2023-09-10 21:37:06 星期日 发表于北京 阅读:1718
 Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。 三大数据结构分别是: `RDD`:弹性分布式数据集 `累加器`:分布式共享只写变量 `广播变量`:分布式共享只读变量 #### RDD介绍与原理 RDD (Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。 ##### 弹性 >存储的弹性:内存与磁盘的自动切换; 容错的弹性:数据丢失可以自动恢复; 计算的弹性:计算出错重试机制; 分片的弹性:可根据需要重新分片。 ##### 分布式:数据存储在大数据集群不同节点上 ##### 数据集:RDD封装了计算逻辑,并不保存数据 ##### 数据抽象:RDD是一个抽象类,需要子类具体实现 ##### 不可变:RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的RDD里面封装计算逻辑 ##### 可分区、并行计算 #### RDD的创建 在 Spark 中创建 RDD 的创建方式可以分为四种,在实际生产环境中一般用到前两种 ##### 从集合(内存)中创建 RDD 从集合中创建 RDD,Spark 主要提供了两个方法:parallelize 和 makeRDD ``` def main(args: Array[String]): Unit = { // local[*]表示程序的并行度为当前机器的cpu核数 // local表示单线程执行 val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD") val sc = new SparkContext(sparkConf) // 从内存中的数据创建RDD val seq = Seq[Int](1, 2, 3, 4, 5) val rdd = sc.makeRDD(seq) rdd.collect().foreach(println) sc.stop() } ``` ##### 从外部存储(文件)创建 RDD 由外部存储系统的数据集创建 RDD 包括:本地的文件系统,所有 Hadoop 支持的数据集, 比如 HDFS、HBase 等。 ``` package cn.libins.learn.spark.core.rdd import org.apache.spark.{SparkConf, SparkContext} object CreateRDDFromFile { def main(args: Array[String]): Unit = { // local[*]表示程序的并行度为当前机器的cpu核数 // local表示单线程执行 val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD") val sc = new SparkContext(sparkConf) // 1、path可以只传目录,表示把当前目录下的所有文件的读取出来 // 2、可以传入正则表达式 // 3、可以传入HDFS路径 val rdd = sc.textFile("data/WordCount.txt") // 以行为单位读取数据 // val rdd = sc.wholeTextFiles("data") 以文件为单位读取数据,可以区分数据来自哪个文件 rdd.collect().foreach(println) sc.stop() } } ``` ##### 从其他 RDD 创建 主要是通过一个 RDD 运算完后,再产生新的 RDD。 ##### 直接创建 RDD(new) 使用 new 的方式直接构造 RDD,一般由 Spark 框架自身使用。 ##### RDD并行度与分区 默认情况下,Spark 可以将一个作业切分多个任务后,发送给 Executor 节点并行计算,而能够并行计算的任务数量我们称之为并行度。这个数量可以在构建 RDD 时指定。 记住,这里的并行执行的任务数量,并不是指的切分任务的数量,不要混淆了。如果系统只有1个可用内核,但是用户还是设置了多个分区,那么这些分区的并行度其实还是1 示例:从内存中创建一个RDD,并设置3个分区 ``` package cn.libins.learn.spark.core.rdd import org.apache.spark.{SparkConf, SparkContext} object RDDPartitonFromMem { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD") val sc = new SparkContext(sparkConf) // 创建具有3个分区的RDD val seq = Seq[Int](1, 2, 3, 4, 5, 6, 7, 8) // RDD的分区数通过传入numSlices参数来确定分区数 // 如果numSlices参数不传入,则默认获取当前机器的CPU核数 val rdd = sc.makeRDD(seq, 3) // 通过输出文件个数来判断分区个数 rdd.saveAsTextFile("data/output") sc.stop() } } ``` 在指定的位置生成了3个文件 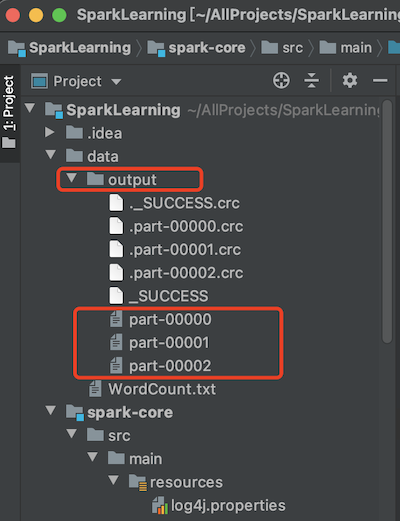

 京公网安备 11010902000544号
京公网安备 11010902000544号