登 录
注 册
< 大 数 据
Flink
Hadoop
Spark
Hive
HBase
Kafka
其他框架
Spark简介
Spark开发环境初始化
Spark运行架构与核心组件
Spark RDD详解
Spark RDD转换算子-单Value类型
Spark RDD转换算子-其他类型
Spark RDD行动算子
Spark Shuffle的设计思想
Spark SQL Hints用法总结
热门推荐>>>
中台架构
中台建设与架构
Hadoop
源码分析-NN启动(三)
HBase
HBased对接Hive
Linux
Nginx高可用
Python
数据导出工具
Flink
3分钟搭建Flink SQL测试环境
Kafka
Kafka对接Flume
深度学习
卷积神经网络
数据结构与算法
选择合适的算法
MySQL
数据备份恢复
计算机系统
信号量同步线程
Hive
Hive调优参数大全
其他框架
Azkaban Flow1.0与2.0
ClickHouse
表引擎-其他类型
技术成长
最好的职业建议
精选书单
技术成长书单—机器学习
技术资讯
数据在线:计算将成为公共服务
开发工具
IntelliJ IDEA 20年发展回顾(二)
系统工具
Mac命令行工具
虚拟化
内存虚拟化概述
云原生
云原生构建现代化应用
云服务
一文搞懂公有云、私有云...
Java
Spring Boot依赖注入与Runners
Go
Go函数与方法
SQL
SQL模板
当前位置:
首页
>>
Spark
>>
Spark Shuffle的设计思想
Spark Shuffle的设计思想
2023-10-28 17:17:16 星期六 发表于北京 阅读:1764
 Shuffle解决的问题**`是如何将数据重新组织,使其能够在上游和下游task之间进行传递和计算`** 如果是单纯的数据传递,则只需要将数据进行分区、通过网络传输即可,没有太大难度,但Shuffle机制还需要进行各种类型的计算(如聚合、排序),而且数据量一般会很大 如何支持这些不同类型的计算,如何提高Shuffle的性能都是Shuffle机制设计的难点问题 #### 再谈宽依赖(ShuffleDependency)和窄依赖(NarraowDependency) 宽依赖(ShuffleDependency)和窄依赖(NarraowDependency)的区别是child RDD的各个分区中的数据是否完全依赖其parent RDD的一个或者多个分区。 `完全依赖`指parent RDD中的一个分区不需要进行划分就可以流入child RDD的分区中。 - 如果是完全依赖,那么数据依赖关系是窄依赖。 - 如果是不完全依赖,也就是parent RDD的一个分区中的数据需要经过划分(如HashPartition或者RangePartition)后才能流入child RDD的不同分区中,那么数据依赖关系是宽依赖。 注意两种容易混淆的依赖方式 ##### ManyToManyDependency 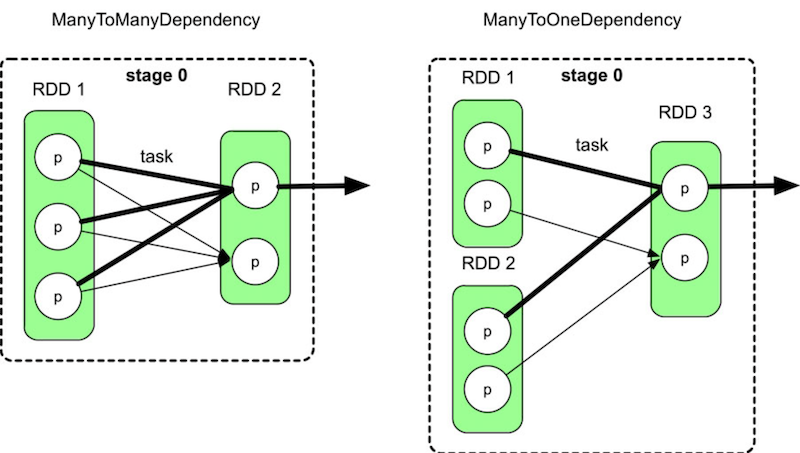 ##### ShuffleDependency 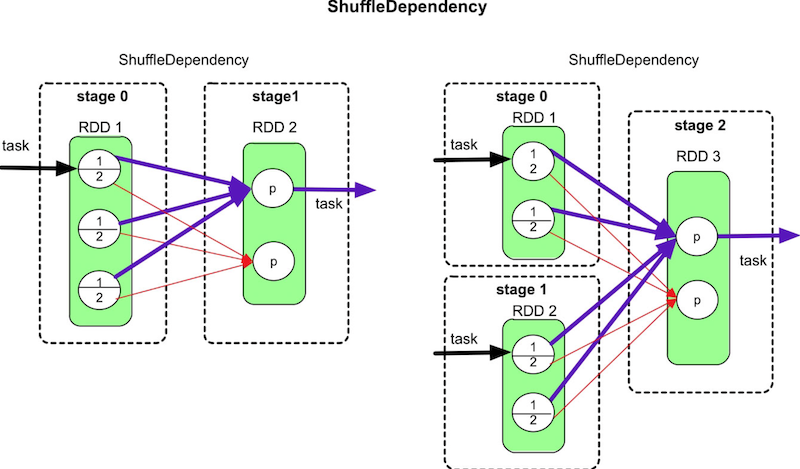 虽然ManyToManyDependency形似ShuffleDependency,却属于NarrowDependency,因此Spark将parent RDD和child RDD组合为一个stage #### Shuffle数据分区数问题 该问题针对Shuffle Write阶段。如何对map task输出结果进行分区,使得reduce task可以通过网络获取相应的数据? ###### 如何确定分区个数? 如果用户没有定义,则默认分区个数是parent RDD的分区个数的最大值,分区个数与下游stage的task个数一致 ###### 如何对map task输出数据进行分区? 对map task输出的每一个record,根据Key计算其partitionId,具有不同partitionId的record被输出到不同的分区(文件)中 #### 数据聚合问题 该问题针对Shuffle Read阶段,即如何获取上游不同task的输出数据并按照Key进行聚合呢 `数据聚合的本质是将相同Key的record放在一起,并进行必要的计算`,这个过程可以利用C++/Java语言中的HashMap实现。 方法是使用两步聚合(two-phaseaggregation): >1、将不同tasks获取到的record存放到HashMap中,HashMap中的Key是K,Value是list(V) 2、对于HashMap中每一个record,使用func计算得到record #### Shuffle Sort问题 有些操作如sortByKey()、sortBy()需要将数据按照Key进行排序,那么如何在Shuffle机制中完成排序呢? ###### (1)在哪里执行sort? 首先,在Shuffle Read端必须执行sort,因为从每个task获取的数据组合起来以后不是全局按Key进行排序的。 其次,理论上,在Shuffle Write端不需要排序,但如果进行了排序,那么Shuffle Read获取到(来自不同task)的数据是已经部分有序的数据,可以减少Shuffle Read端排序的复杂度。 ###### (2)何时进行排序 |排序类型|描述|优点|缺点| |-|-|-|-| |先排序再聚合|先使用线性数据结构如Array,存储Shuffle Read的record,然后对Key进行排序,排序后的数据可以直接从前到后进行扫描聚合,不需要再使用HashMap进行hash-based聚合|这种方案也是Hadoop MapReduce采用的方案,方案优点是既可以满足排序要求又可以满足聚合要求|需要较大内存空间| |排序和聚合同时进行|使用带有排序功能的Map,如TreeMap来对中间数据进行聚合,每次ShuffleRead获取到一个record,就将其放入TreeMap中与现有的record进行聚合,过程与HashMap类似,只是TreeMap自带排序功能|排序和聚合可以同时进行|相比HashMap,TreeMap的排序复杂度较高,TreeMap的插入时间复杂度是 O ( n log n ),而且需要不断调整树的结构,不适合数据规模非常大的情况| |先聚合再排序|维持现有基于HashMap的聚合方案不变,将HashMap中的record或record的引用放入线性数据结构中进行排序|聚合和排序过程独立,灵活性较高,而且之前的在线聚合方案不需要改动|需要复制(copy)数据或引用,空间占用较大| #### 内存不足问题 `Shuffle数据量过大导致内存放不下怎么办?` 由于使用HashMap对数据进行combine和聚合,在数据量大的时候,会出现内存溢出。这个问题既可能出现在ShuffleWrite阶段,又可能出现在Shuffle Read阶段。 **`解决方案:使用内存+磁盘混合存储`** 先在内存(如HashMap)中进行数据聚合,如果内存空间不足,则将内存中的数据spill到磁盘上,此时空闲出来的内存可以继续处理新的数据。此过程可以不断重复,直到数据处理完成 然而,问题是spill到磁盘上的数据实际上是部分聚合的结果,并没有和后续的数据进行过聚合。因此,为了得到完整的聚合结果,我们需要在进行下一步数据操作之前对磁盘上和内存中的数据进行再次聚合,这个过程我们称为“全局聚合” 为了加速全局聚合,我们需要将数据spill到磁盘上时进行排序,这样全局聚合才能够按顺序读取spill到磁盘上的数据,并减少磁盘I/O 参考书籍:[大数据处理框架Apache Spark设计与实现(全彩)](https://book.douban.com/subject/35140409/ "大数据处理框架Apache Spark设计与实现(全彩)")

 京公网安备 11010902000544号
京公网安备 11010902000544号